23 min read
The AI-Pilled Operating Company
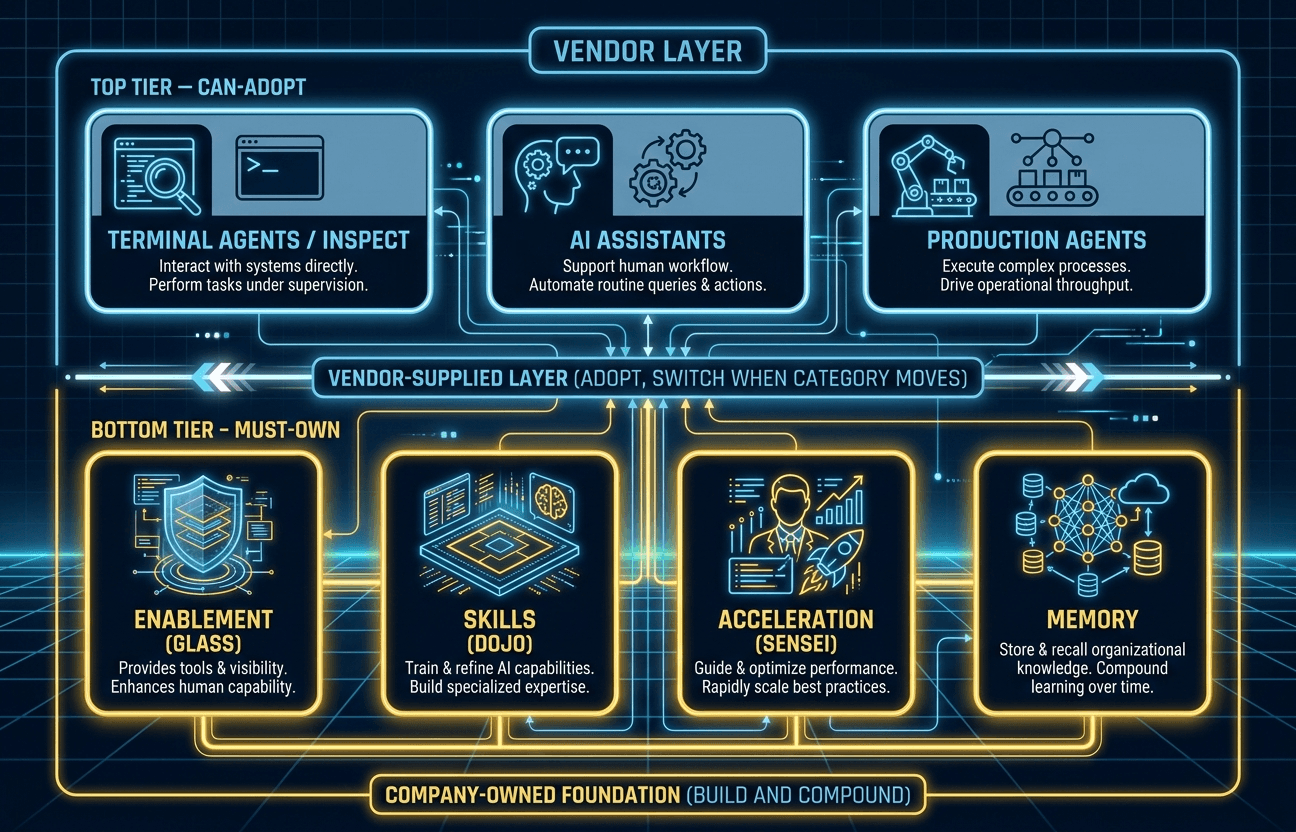
Every company is adopting AI. Most are renting it. A seven-primitive diagnostic separates the organizations building durable capability from those buying tools they will eventually need to replace. Four primitives you must own — enablement, skills, acceleration, memory — and three you can adopt from the market. The vendors are doing good work. That is precisely the trap.

They say it in the Monday exec meeting like the decision has already been made.
"We're all-in on AI."
Nobody objects. Why would they? The company bought the licenses. A few people have good prompt threads. One team has a chatbot in Slack. IT is reviewing another vendor. Someone volunteers to run training. The sentence sounds modern, ambitious, responsible.
Then the meeting ends.
Sales still has no clean way to hand context to an assistant. Product still has no shared library of workflows worth reusing. Engineering has a coding agent, but it lives on a few power-user laptops. The best operating habits in the company are still sitting in people's heads, or buried in docs nobody can find. Everyone says the company is moving fast. Underneath, it is still improvisation.
I've seen versions of this moment too many times now. Smart leaders. Real budgets. Good intentions. But the mental model is wrong.
Being AI-pilled is not "we bought access to frontier models." It is not "we rolled out Copilot." It is not "a few cracked people are getting absurd leverage in the corner." Those are inputs. Useful ones. But they are not an operating company.
The better frame is a ledger.
On one side are the primitives you can adopt: terminal agents, AI assistants, production agents. Let the market move here. Anthropic, OpenAI, Google, Microsoft, and the startups around them are doing good work. Use the best tools you can. Switch when the category moves. Don't turn fast-moving product categories into religion. These already work good enough today to move real work — and that is exactly the trap this article is about.
On the other side are the primitives you have to own: enablement, skills, acceleration, memory. The front door. The playbook. The matching and coaching layer. The context substrate. These are not vendor features. These are the parts that make the tools mean something inside your company.
That is why Ramp is useful as a primer. Not because every company should copy Ramp, and not because this piece needs another Ramp profile. Ramp just makes the distinction visible. Their stack has names. Most companies have the same need, just without the nouns yet.
There are only two types of companies right now:
— Moe Ali (@ProductFaculty) April 13, 2026
1. Ramp
2. Board committees arguing whether we should give employees a $20/mo subscription https://t.co/j8JOXh5dE3
If you're honest, this is the diagnostic. Do you have a few impressive AI users, or do you have an operating system for AI work? Can a new person join, sign in, find the right workflows, inherit context, and get leverage on day one? Or does everything still depend on who happens to be curious, technical, and willing to duct-tape it together?
The companies that get this right will win not because their assistant is a little better. They will win because their people, context, and workflows compound. That is the split this article is about.
The Seven Primitives
Looking across companies that have moved past the experiment phase, a pattern emerges. There are seven capabilities that define an AI-native organization — and they split into two sides based on a single question: does this need to be yours, or can you rent it?
Four primitives sit on the must-own side. These are custom per organization, tied to competitive advantage, and dangerous to outsource:
- Enablement — the infrastructure that makes AI accessible to everyone: authentication, permissions, tool provisioning, guardrails. The front door.
- Skills — codified institutional knowledge that teaches AI how your organization works. Not generic prompts. Your processes, written by the people who do the work.
- Acceleration — the distribution and change management layer that gets the right capability to the right person at the right moment. Part automated, part human.
- Memory — organizational context made legible to agents. The accumulated knowledge that turns a cold-start AI interaction into one that already understands your business.
Three primitives sit on the can-adopt side. These will see fierce vendor competition, rapid improvement, and commoditization pressure:
- Terminal Agents — coding and analysis tools. Claude Code, Codex, Gemini CLI. Adopt the best available, be ready to switch.
- AI Assistants — personal AI for daily work. Applications that run on the enablement layer, not replacements for it.
- Production Agents — autonomous, task-specific agents that handle narrow workflows in production. Expense enforcement, data reconciliation, compliance checks.
The must-own side gets the deep treatment in the sections that follow. The can-adopt side gets lighter coverage — not because it matters less, but because the market is solving it good enough. That's the point. And that's the trap.
Must-Own: Enablement
Glass is the least glamorous primitive in this whole framework. That is exactly why it matters.
Most companies want the assistant, the demo, the screenshot, the story about how one cracked employee got absurd leverage in a weekend. Very few want to own the layer underneath: who can use what, how tools get provisioned, which systems are reachable, what context can move where, and how a new employee gets from zero to useful without filing three tickets. But that layer is the difference between "some people use AI" and "the company can actually operate with AI."
Ramp makes that distinction visible. Their name for the layer is Glass. In the baseline notes, Glass sits over SSO, permissions, tool provisioning, and internal-system connectivity. It is not the assistant. It is the platform the assistant runs on. That distinction matters. Glass reportedly reached 700 daily active users within a month, inside a broader 99.5% staff AI adoption story (who are the 8 holdouts??!). That is not a model-quality story. That is a friction-removal story.
99% of Ramp uses ai daily. but we noticed most people were stuck — not because the models weren't good enough, but because the setup was too painful and unintuitive for most. terminal configs, mcp servers, everyone figuring it out alone.
— Eric Glyman (@eglyman) April 12, 2026
so we built Glass. every employee gets a… https://t.co/SHgd099df4
Before we go deeper: "must own" does not mean "must build from scratch." You do not need a proprietary Glass engineered in-house. What matters is that Glass behaves as a protocol, not a product. The implementation can be a third-party host, an open-source project you self-host, or even Microsoft or Google operating it on your behalf — as long as the resulting platform is interoperable with every frontier model and every model harness, not just the vendor's own. The failure mode to avoid is outsourcing Glass to the same company that sells you the model. If Anthropic hosts your Glass, your Glass works great with Claude and grudgingly with everyone else. If Microsoft hosts it, it works great with Azure OpenAI and grudgingly with everyone else. That is the trap. The enablement layer must stay neutral even if you pay someone else to run it.
There is a second, quieter point. The enablement layer is the one must-own primitive that is genuinely technical — IT accountability lives here, integrations live here, the long tail of internal apps lives here, and nobody outside your company cares enough to fight for your specific stack the way you will. The other three must-own primitives — skills, acceleration, memory — are mostly context engineering. That is core to your business. No vendor, no matter how helpful, can be as rich in your context as you are. Both sides require accountability, but the shape of the accountability differs.
The cleanest way to think about Glass is the concentric-circles model.
Circle 1: workspace identity. Start with the system employees already live in. Email, docs, chat, calendar, core SaaS. If this ring is broken, every AI rollout turns into access drift, one-off setup, and support tickets.
Circle 2: identity bridges. Real companies do not live in one neat stack. They have specialist SaaS, acquired systems, partner portals, custom apps. The second ring is the bridge layer that makes those systems feel coherent to the user even when the backend is messy.
Circle 3: legacy bridges. Every operating company has some version of the server-in-the-closet problem. Important systems that were never designed for modern auth, modern APIs, or agents at all. Glass still has to reach them. Not elegantly. Reliably.
Circle 4: agent identity. This is the new ring. Agents are not quite users and not quite services. They act on behalf of people, but they run with machine speed and persistence. If you do not give them a governed identity model, they either end up overprivileged or remain toys.

The hardest part of Glass is not any single ring. It is keeping the platform interoperable across the three can-adopt primitives — terminal agents, assistants, production agents — when every major cloud provider has an incentive to prevent exactly that.
Microsoft and Google both ship full workspace suites (M365, Workspace) and full cloud platforms (Azure, GCP). Their revealed preference is to pull every layer inside — the model, the assistant, the orchestration, the identity, the skills store, the marketplace. The business pattern is not sinister; it is the Apple playbook applied to AI. Own the hardware, the OS, the app store, the apps — the rest follows. AWS plays this differently because it does not have a comparable end-user suite — its posture is closer to Android: stay neutral as the substrate, let the applications live elsewhere, and win on reach rather than vertical capture. None of the three is the villain. They are responding to their own economics. But operators need to know which posture each vendor is optimizing for, because that shapes what Glass has to absorb.
Saying "adopt the best and swap when something better arrives" is a simple sentence that hides real work. Portability is earned: through clean abstractions at the assistant and agent boundaries, through insistence on open identity standards (OIDC, SAML, OAuth 2.1 for agents), through refusing to let any single vendor own the skills store or the orchestration layer. It is hard. It is worth it. The alternative is a decade of quiet dependency that nobody notices until switching costs have already compounded.
That is why Glass is must-own. Frontier vendors can provide excellent assistants, excellent models, and excellent agent runtimes. They should. But the company has to own the entry point into its own context. Otherwise every new AI tool becomes one more disconnected window, and the organization mistakes tool sprawl for transformation.
Glass is not the flashy part of the stack. It is the part that makes the rest of the stack real.
Must-Own: Skills
If Glass is the front door, Dojo is what makes going through the door worth it.
A company can buy the best model on the market and still get mostly generic output. That is not a model problem. It is a context problem. The skills layer is where general intelligence gets taught how your company actually works: how you prep for a board meeting, investigate a churn risk, write a spec, qualify a lead, or close the books. Not as a one-off prompt somebody pasted into chat six months ago, but as a reusable operating asset.
That is what makes Dojo different from a prompt library.
A prompt library is usually just a pile of clever incantations. Helpful, sometimes. Portable, maybe. But still thin. It does not tell the model what good looks like in your environment. It does not encode sequence, judgment criteria, edge cases, escalation points, or tool choices. A real skills system does. Ramp's public materials describe Dojo as a company-wide marketplace of 350+ shared skills, written in markdown, versioned in Git, and reviewed more like code than copy. That is a different category entirely.

We Built Every Employee at Ramp Their Own AI Coworker
Inside Ramp's Glass, Dojo, and Sensei infrastructure — the internal platform that made 99.5% AI adoption possible.
The payoff is not just reuse. It is compounding.
Once a strong operator figures out a workflow, that workflow no longer has to die with the person who discovered it. It can become the new baseline for everyone else. The next product manager starts from the best customer-research skill already written. The next account executive starts from the best call-prep workflow already tested. The next engineer starts from the best debugging pattern already documented. Tacit know-how becomes organizational infrastructure.
This is also where the ownership argument gets sharpest. If your best workflows live in someone else's marketplace, memory layer, or vendor environment, you are slowly exporting what makes the company distinctive. Samsung is the clean cautionary example. In 2023, within roughly 20 days of opening access to ChatGPT, engineers pasted proprietary source code, test sequences, and confidential meeting content into the system. The immediate problem was security. The deeper problem was boundary failure: institutional knowledge crossed the line because there was no company-owned skills boundary strong enough to catch it first.
Samsung banned external AI tools after the leak and built their own. By early 2026 they had shipped Samsung Gauss (frontier model), Sirius (multimodal knowledge-graph search), and DoXA (document analysis). The Galaxy S26 runs Gauss alongside Gemini and Perplexity. What started as a cautionary moment became a forcing function — they moved the must-own side from zero to owned-at-scale in under three years. The instinct was correct. The execution followed.
That is why Dojo belongs on the must-own side of the ledger. Vendors should absolutely compete to give you better models, better assistants, and better runtimes. But your playbooks should remain yours. The company that owns its skills owns the compound returns from every good workflow it discovers.
Must-Own: Acceleration
The acceleration layer is the one most companies skip — and the reason most AI adoption programs stall.
The organizations I have watched move past the experiment phase tend to have two components working in concert. The first is automated: an engine that matches the right capability to the right person at the right moment. Ramp calls this Sensei. It sits inside Dojo, analyzes role, connected tools, and recent work, and surfaces the five skills most likely to matter. A new account manager does not browse a catalog of 350 skills. Sensei delivers the five that matter on day one.
The second component is human. Even Ramp — with 1,500 employees and hundreds of engineers — runs coached hackathons with 800 participants and 100 internal engineering and product coaches. They built an L0-through-L3 proficiency framework that publicly measures team progression. L0 is no meaningful AI usage. L3 is building with AI. Public measurement creates social proof. When your team sees three other teams at L2 and you are at L1, the incentive is competitive, not punitive. That is a different motivational mechanism than a manager telling you to log more tool hours.
Morgan Stanley took a different path to the same destination. Rather than building a recommendation engine, they built internal prompt engineering teams, formal AI governance committees, and a controlled-content strategy — every AI tool feeds exclusively on internally published, vetted material. The result: 98% of 15,000+ financial advisors actively use the firm's AI chatbot. No vendor owns the change management relationship. Morgan Stanley retained the institutional knowledge, the training methodology, and the governance framework.
The pattern is consistent across both examples. Technology companies have historically not wanted to do this kind of work — it is services-heavy, deeply embedded, and hard to scale like software. They will increasingly try. AI vendors are already pushing deployed engineers and executives inside customer organizations. When your technology vendor also owns your change management relationship, the capability that makes you competitive becomes dependent on a single provider.
The acceleration layer works because it is close to the work — built by people who understand both the business and the tools, owned by the organization that compounds the capability, and designed to make itself progressively less necessary as proficiency spreads. Outside help can seed this layer. It cannot replace it. The company that depends on its consultants to run AI adoption does not have AI adoption; it has a contract.
Automated matching handles distribution. Human coaching handles judgment. Neither works alone. Both must be company-owned.
Must-Own: Memory
Memory is the primitive that makes the other six compound. Without it, every AI interaction starts cold. Every agent session begins from scratch. Every insight evaporates at the end of a conversation.
The Missing Protocols covered the harness-layer version of this question — interoperability between tools. The primitives in this piece operate at the company-capability layer. Same direction, different altitude.
The word "memory" undersells what this layer actually does. It is context engineering — the deliberate capture, refinement, and activation of organizational knowledge so that agents and humans operate with the same situational awareness. The cleanest vocabulary for this layer already exists in the open-source Letta framework (originating from the MemGPT paper, Berkeley, 2023). Borrow it rather than inventing new names:
Core memory. The always-in-context layer. Rules, instructions, guardrails — the never-do-this and always-do-this constraints that govern every interaction. Compliance requirements, brand voice, escalation paths, access boundaries. Small. Loud. Loaded on every turn.
Recall memory. The chat-history layer. Everything that has been said inside an agent session, semantic-search-accessible at runtime rather than dumped wholesale into the prompt. What happened in the last conversation, the last sprint, the last client meeting. Without it, agents re-ask questions humans already answered.
Archival memory. The procedural-plus-wiki layer. How this company actually does things — not what the playbook says in theory, but what actually works — combined with the organizational substrate of client histories, product documentation, competitive intelligence, and institutional decisions. Stored externally in a vector-retrievable form. The layer that most companies believe they already have. They do not. They have fragments scattered across Notion, Confluence, Google Drive, and the heads of people who might leave.
Tools. Sitting one layer above memory: the skills system (Dojo, in Ramp's vocabulary). Skills are the tightly-integrated, agent-runtime-callable workflows — how to execute, not what to know. Dojo captures what the company knows how to do. Memory captures the context that makes those skills effective in a specific situation, for a specific person, at a specific moment. Dojo is the playbook. Memory is knowing which play to run.
What makes this layer compound is elevation. A memory starts personal — one user's session, one user's note, one user's correction. The next layer votes on whether it deserves to graduate: user → team → department → division → company. Good notes bubble up. Bad notes get downvoted with a reason — outdated, wrong_context, contradicted_requirements, caused_bug — so the system learns what to deprioritize, not just what to elevate. Humans review and refine skills and wiki entries. Agents activate memory automatically at runtime. Both sides have to show up.
The ownership argument is simple. When context flows unexamined into vendor environments, it stops being yours. Samsung's engineers did not intend to donate proprietary source code to OpenAI's training pipeline. They were solving problems. The institutional knowledge leaked because no one had built the boundary between company context and vendor tooling. Context engineering is that boundary.
Companies do not need to build the technical plumbing themselves. Session stores, vector databases, retrieval-augmented generation — these are infrastructure commodities. What companies must own is the activation layer: what gets captured, how it gets refined, who controls retrieval, and where the boundary sits between internal context and external tools.
Own your context. Everything else on this ledger depends on it.
Can-Adopt Primitives
Terminal Agents
The can-adopt side starts with terminal agents — the CLI and pair-programmer tools that developers live in daily. Claude Code, Codex, Gemini CLI. Ramp built Inspect internally, but the principle holds even there: this is the layer where vendor competition benefits everyone and switching costs stay low.
The numbers move fast. Ramp's Inspect accounts for roughly half of merged pull requests. Non-engineers now produce 12% of human-initiated code changes. Geoff Charles targets 80-90% AI-written code — what he calls "coding escape velocity." These statistics will look quaint within a year because every vendor in this space is shipping improvements on a weekly cadence.
That velocity is exactly why this sits on the can-adopt side. The frontier moves too fast for any single company to out-engineer the labs at this layer. Adopt the best available tool. Integrate it through your enablement platform. Be ready to swap it when something better arrives. The interoperability question is not "will you switch" — it is "can you switch without losing your institutional context." That is what the must-own side protects.
The framing is not "switch vendors every quarter." It is interoperability. When a model is better at copywriting, route your marketing team's context to that model for that workflow. When a different model is better at agent development, route engineering there. The goal is to let vendors compete on quality per workload, not on end-to-end infrastructure lock-in. Some workloads one vendor wins. Other workloads a different one wins. You should be allowed to pick the right tool for each job — which requires a company-owned context layer that moves with you, not a vendor-owned context layer that holds you in place.
AI Assistants
AI assistants are the conversational layer — the tools employees talk to throughout their day. OpenClaw, Hermes, NanoBot — plus the features Anthropic has been shipping into Claude Code itself over the last three months: Scheduled Tasks (February), Remote Control (February), Background Agents (v2.0.60), Claude Cowork (winter), and most recently Routines and Managed Agents (April). Functionally similar patterns — context, schedule, and autonomous execution — moving into the vendor's own harness. At Ramp, the personal assistant is built on Anthropic's Claude Agent SDK and tightly integrated with Glass.
The critical distinction is modality. Terminal agents are pair-programmers — they work inside development environments on structured tasks. AI assistants are general-purpose conversational tools — they draft emails, summarize meetings, answer questions, brainstorm approaches. Different interaction pattern, different context needs, different replacement curves.
Most companies will adopt a vendor's assistant rather than building their own. That is the right call. But the enablement platform the assistant runs on — the authentication, the permissions, the internal-system connectivity — that should be company-owned. An AI assistant without context from your enablement layer is a general-purpose chatbot. An AI assistant wired into your Glass equivalent knows your projects, your colleagues, your constraints. The difference is not the model. It is the substrate.
Swap the assistant when something better arrives. Keep the platform it runs on.
Production Agents
Production agents are the narrowest primitive on the ledger — self-contained automated agents that handle specific tasks without human supervision. Expense policy enforcement. Accounts payable auto-coding. Accounting reconciliation. Ramp has shipped over a dozen. Their controller agents catch 15x more out-of-policy spend with 99% accuracy, escalating only 10-15% of cases for human judgment.
This layer is commoditizing fast. Open standards — MCP, A2A, AGENTS.md — are converging under the Linux Foundation's Agentic AI Foundation. The risk is not that the protocols fragment. The risk is that orchestration layers — Microsoft's Agent 365, Google's Vertex AI — become the new lock-in points even as the underlying protocols stay open. Companies that interoperate through open protocols today retain the option to switch tomorrow.
The Missing Protocols covered the protocol-level version of this problem. The company-level version is the same argument, one layer up.
The Primer: What Ramp Chose to Own
You have already seen most of Ramp's story threaded through the must-own sections above. The primer here is the short version for anyone who wants the mapping on one page.
| Primitive | Ramp's name | What it is |
|---|---|---|
| Enablement | Glass | One pane over SSO, permissions, tool provisioning, and internal-system connectivity. 700 DAU in month one. |
| Skills | Dojo | 350+ reusable skill files, versioned in Git, reviewed like code, curated by the people who do the work. |
| Acceleration | Sensei | Automated skill-matching plus coached hackathons (800 participants, 100 internal coaches) and a public L0–L3 proficiency ladder. |
| Memory | unnamed, but real | Personal memory built on first open from authenticated connections (via Glass + Okta SSO scope). Agent sessions inherit organizational context automatically. Inspect wires into Sentry, Datadog, GitHub, Slack, Buildkite. |
| Terminal Agents | Inspect | Internally built coding agent. ~30–50% of merged PRs. 12% of human-initiated code changes from non-engineers. |
| AI Assistants | on Glass | Built on Anthropic's Claude Agent SDK. An application on the platform, not the platform itself. |
| Production Agents | a dozen+ | Controllers catching 15x more out-of-policy spend at 99% accuracy. Expense, AP, accounting. Toby (call-analytics agent, analyzing ~50k sales calls). |
The takeaway is not "become Ramp." It is: notice what they refused to outsource.
Other Operators Worth Watching
Ramp is not the only example. Two contrasting cases round out the pattern: one that applied must-own thinking by executive mandate, and one that skipped the must-own side entirely.
Shopify declared in April 2025 that "reflexive AI usage is now a baseline expectation." CEO Tobi Lütke's company-wide memo added AI usage questions to performance reviews and required teams to demonstrate why AI cannot accomplish a task before requesting new headcount. This is acceleration-layer thinking applied top-down rather than bottom-up. Unlike Ramp's proficiency ladder, Shopify chose executive expectation-setting. Both approaches work. Both require deliberate organizational action.
Reflexive AI Usage Is Now a Baseline Expectation at Shopify
Company-wide memo adding AI usage questions to performance reviews and requiring teams to demonstrate why AI cannot accomplish a task before requesting new headcount.
Klarna is the cautionary example. The fintech replaced roughly 700 customer service roles with an AI assistant and cut headcount by 40%. CEO Sebastian Siemiatkowski later admitted the company "probably over indexed" — service quality degraded, product velocity slowed, and Klarna began rehiring. Klarna adopted production agents without investing in enablement, skills, or acceleration. The result was the replacement trap: short-term efficiency followed by quality collapse.
The framework does not say every company must build what Ramp built. It says: know which side of the ledger you are investing in, and make sure the must-own side is not empty.
The Pattern Is Not New
Every major technology transition of the past thirty years forced the same decision: what do you own, and what do you adopt? The consequences of getting it wrong were severe and consistent.
| Era | What Companies Outsourced | What They Should Have Owned | Cost of Getting It Wrong |
|---|---|---|---|
| ERP | Process knowledge to consultants | Process documentation, change management | FoxMeyer bankrupt; Hershey $100M missed orders; Lidl 500M EUR wasted |
| Cloud | Infrastructure to hyperscalers | Architecture decisions, portability | GEICO 2.5x cost overrun; Apple $50M egress fees |
| SaaS | Data ownership to vendors | Data sovereignty, export capability | Nirvanix 2-week shutdown; Builder.ai sudden collapse |
| Consulting | Strategy and execution to Big 4 | Internal capability, knowledge transfer | Hertz $32M wasted; 80% digital-transformation failure rate |
| Open vs. Proprietary | Standards to dominant vendors | Interoperability, open protocols | Reversed only by SQL, HTTP, REST, Linux |
| AI (Now) | Context and intelligence to vendors | Enablement, skills, acceleration, memory | 95% of pilots deliver zero ROI (MIT, 2025) — but the 5% own the left side of the ledger |
In every case, open standards eventually provided the escape hatch. The current AI equivalent is forming: MCP, A2A, and AGENTS.md under the Linux Foundation's Agentic AI Foundation. The pattern that breaks vendor capture is the same pattern it has always been — interoperability at the protocol layer, ownership at the capability layer.
The companies that survived each transition treated the technology as something to adopt but the institutional knowledge, process ownership, and strategic flexibility as something to own.
The Good Enough Trap
The easy version of this argument would be to invent a villain.
I do not think that is right.
When I say the risk is not a villain, I am being specific about who I mean: the frontier-model companies (Anthropic, OpenAI, Google) and the hyperscaler-plus-application vendors (Microsoft, AWS). They are doing genuinely great work. They made frontier models available at useful quality and price, which created this era at all. Then they wrapped those models in what I will call the model harness — a feature set that gives developers understandable patterns for invoking the model: system prompts, tool use, streaming, structured output, caching. Also great. Now they are extending further, into what I will call the agent harness — a layer that fuses context and model-harness capabilities so that execution happens on their servers, in their environment, activated by their tooling.
This is where it gets subtle. Context starts living server-side. That context is most easily activated by the same vendor's model harness. Their model harness runs their model. What starts as "Anthropic made a very useful agent feature" ends as "your operating context is now most easily retrievable inside Anthropic's infrastructure, via a harness that only really runs Claude." They did not plan this as capture. It is the natural shape of driving frontier-model consumption, which is their core business. And honestly, without their willingness to push into this territory, many organizations would never have seen that there is a there there at all.
The question is whether now — after the concept has proliferated, after the early wins are real, after "AI can actually do this" has been demonstrated — is the right time to keep letting a single vendor own the agent-harness layer end-to-end. I do not think it is. The frontier model I will happily rent. The model harness I can live with. The agent harness, and everything around the agent harness that will keep accreting context, is where operators need to start pulling the line back.
The risk is not that the vendors are malicious. The risk is that they are useful. Useful enough that companies stop one layer too early. They adopt the assistant, the agent, the memory feature, the workflow layer, and the evaluation loop, then tell themselves they have become AI-native. In the short run, that can look true. Work gets faster. People get leverage. The demos are real.
But over time, something subtler happens.
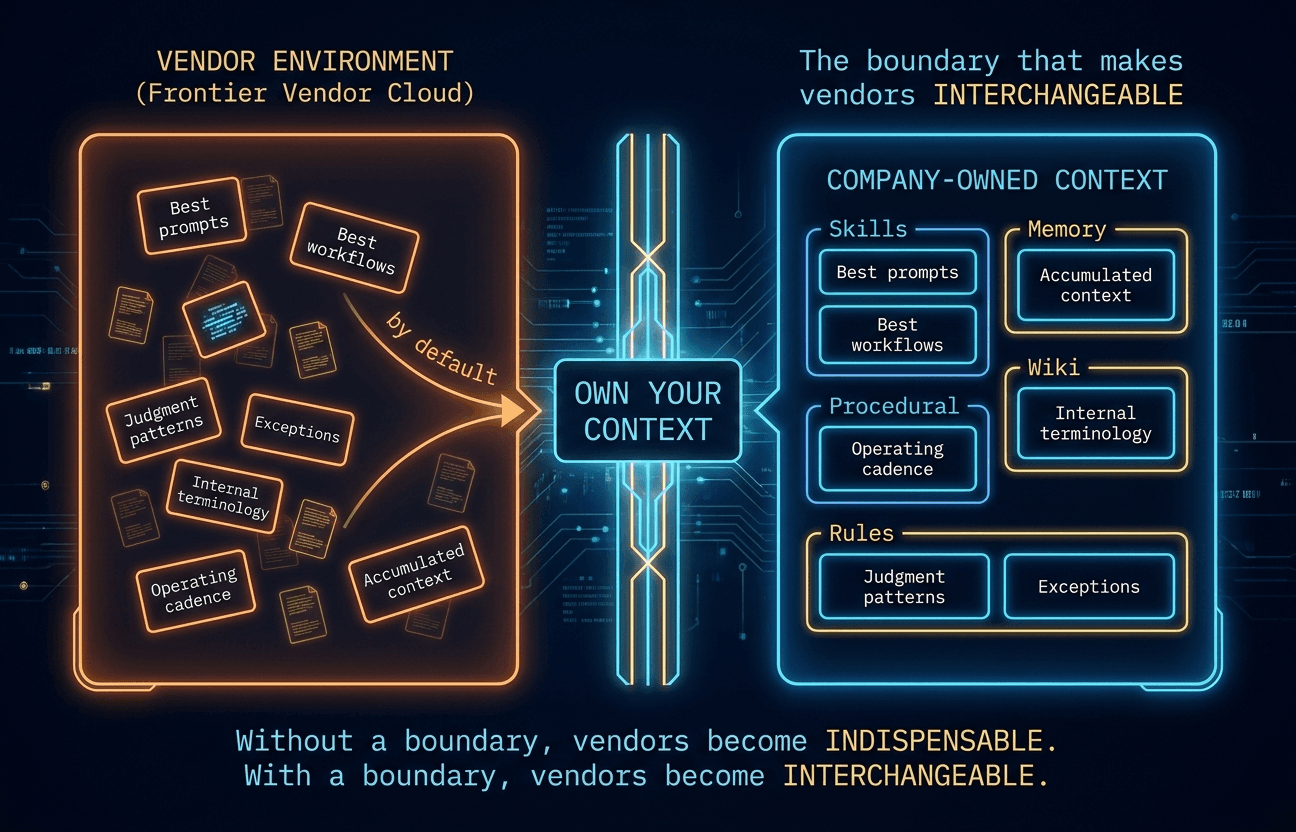
The best prompts live there. The best workflows live there. The judgment patterns, exceptions, internal terminology, operating cadence, and accumulated context start living there too. Not because anyone signed a dramatic exclusivity agreement. Just because that was the easiest place to leave them. Silent vendor capture does not usually arrive as a hostile act. It arrives as convenience.
That is the trap. "Good enough" delays the work of ownership.
The long-term differentiator will not be access to frontier models. Everyone serious will have that. It will not be access to coding agents or AI assistants either. Those will keep improving, and they will keep getting cheaper. The differentiator will be the company-owned layer around them: the skills your operators compound, the memory your systems preserve, the context boundary you defend, and the routing logic that determines how intelligence actually enters work.
So the right posture is cooperative, not adversarial.
Let the vendors compete to build the best models, the best assistants, and the best execution layers. Adopt those gains. Switch when the market moves. Benefit from the R&D you did not have to fund yourself.
But own your context.
Own the layer that makes your company yours.
That means interoperable skills instead of trapped workflows. Company memory instead of scattered chat residue. Neutral protocols instead of hidden dependency. It means building enough of the operating system that vendor progress compounds your advantage instead of absorbing it.
The frontier vendors are helping create this era. Good. Use them.
Just do it on your terms.
The Seven-Primitive Diagnostic
Score your own company. One question per primitive. Be honest.
| Primitive | Question | Yes | Starting | No |
|---|---|---|---|---|
| ⟶ MUST-OWN | ||||
| Enablement | Does every employee have frictionless, SSO-gated access to your AI capabilities — or do they file tickets, configure tools, and manage their own setup? | ☐ | ☐ | ☐ |
| Skills | Is your institutional knowledge — how your company actually does things — codified, versioned, and reusable inside your boundary? | ☐ | ☐ | ☐ |
| Acceleration | Do you have both automated skill-matching and human coaching driving AI adoption — or are you relying on tool availability alone? | ☐ | ☐ | ☐ |
| Memory | Does your company own the capture, refinement, and activation of its organizational context — or does that context flow unexamined into vendor environments? | ☐ | ☐ | ☐ |
| ⟶ CAN-ADOPT | ||||
| Terminal Agents | Are your developers using AI coding tools with organic adoption — and can you switch providers without losing workflow? | ☐ | ☐ | ☐ |
| AI Assistants | Is your AI assistant integrated with a company-owned enablement platform — or is it a standalone vendor app with no internal context? | ☐ | ☐ | ☐ |
| Production Agents | Are your automated agents interoperable through open protocols — or locked into a single vendor's orchestration layer? | ☐ | ☐ | ☐ |
Scoring: Count your Yes answers on the must-own side. That number matters more than the total. A company with four must-own primitives and zero can-adopt primitives is better positioned than one with three can-adopt primitives and zero must-own.
The ledger has a direction. Own the left side first.
What To Do With This
Do not turn this into a committee. Do not schedule a workshop.
Print the seven questions. Sit with them for a week. Notice which ones you cannot answer honestly without flinching — those are the primitives where you have the least ownership. Notice where your organization's context flows: into vendor environments, or into systems you control.
Then pick the weakest primitive and do one thing about it this month. Not a transformation program. One concrete investment in one must-own primitive before the month ends.
That is how this starts. With one honest answer.
References
Primary Ramp sources cited in this piece:
- Seb Goddijn — We Built Every Employee at Ramp Their Own AI Coworker. x.com/sebgoddijn/status/2042285915435937816
- Buchan — Thread on Ramp's Glass, Dojo, Sensei infrastructure. x.com/buchan_sm/status/2044524727679566156
- Geoff Charles (VP Product, Ramp) — Thread on Ramp's AI operating model. x.com/geoffintech/status/2042002590758572377
- Zach Bruggeman, Jason Quense, Rahul Sengottuvelu — Why We Built Our Own Background Agent. Ramp Builders blog. builders.ramp.com/post/why-we-built-our-background-agent
- Creator Economy — Inside Ramp: the $32B company betting on AI agents, with Geoff Charles. creatoreconomy.so/p/inside-ramp-the-32b-company-ai-agents-geoff-charles
Related ForgeVista perspective:
- The Missing Protocols — the harness-layer version of the primitives argument: interoperability between tools.
Also published on